This T-SQL Tuesday is hosted by the one and only James Serra – literally my go-to guy for data lakes and BI architecture. I am so tickled to be writing this right when am reading his book on ‘Deciphering Data Architectures: Choosing Between a Modern Data Warehouse, Data Fabric, Data Lakehouse, and Data Mesh’ (small book and easy to get through, recommended). James’s call to us is to blog on career risks we’ve taken.
I am a risk taker.
I strongly believe in doing work that stimulates and energizes you, rather than treating work as just a job. Some people regard this belief as elitist. I don’t.
I come from a poor country, and I have seen firsthand the toll that ill‑suited work takes on people—jobs taken purely to pay the bills, regardless of health, temperament, or personality. We spend eight to ten hours a day at work on average. If we dislike what we do, it is bound to have detrimental effects over time. Wanting work that helps you be creative and does not slowly wear you down is not elitism; it is self‑preservation.
My career reflects that belief.
I began as a COBOL programmer, transitioned to VB, then became a SQL Server DBA. I spent many years as a DBA before moving into a Database Engineering role, and I am now a Data Engineer. I am also close to graduating with a master’s degree in data science, and my next goal is to transition into an AI Ethics role.
Along the way, I took several significant risks.
1. Stepping outside data entirely
Seven years into my DBA role at a healthcare company, I realized the job had stopped helping me grow—financially and intellectually. I left for a cloud architect role at a startup, which turned out not to be what I had hoped. When I tried to move on, I couldn’t find another role that met my needs.
At my former employer, the infrastructure and Windows support team had an open sysadmin position. I had limited sysadmin experience, but I believed I could learn, and the team consisted of people I knew and trusted. I interviewed and got the role.
I worked as a sysadmin for two years. I can’t say I loved it, but I learned a lot —about monitoring, alerting, patching, managing heterogeneous server environments, and, most importantly, teamwork. When I returned to data work, that experience stayed with me and continues to serve me well.
2. Leaving the comfort of deep expertise
My next major risk was moving from a DBA role—where I had significant experience—into a Database Engineering role. I had always leaned toward application DBA work due to my programming background, but I was also experiencing serious burnout from on‑call rotations and constant operational stress.
I wanted a role with no on call, one that allowed me to focus more on building and programming. I found such a role, but it required relocating to another town. I took the risk and moved.
That Database Engineering role turned out to be the best career decision I’ve made. I enjoyed the work immensely and learned more than I could have imagined.
3. Returning to school
Another major risk was pursuing a master’s degree in data science. I have a background in statistics and have always enjoyed working with R and solving analytical problems on the side. Graduate school had long appealed to me, but it was either too expensive or required in‑person attendance—neither of which was feasible.
Post‑COVID, many universities began offering affordable, fully online programs. One of them was the University of Massachusetts. The program fit my budget, and the curriculum aligned perfectly with what I wanted to learn. I enrolled, and I am enjoying the experience.
4. Embracing Databricks and analytics
The most recent risk I took was moving from a Database Engineering role into a Data Engineer role. My organization decided to adopt Databricks as its data lake platform. While I had some exposure to BI in previous roles, I was far from an expert.
The analytics teams were heavily invested in Databricks, and learning it felt like a natural complement to my data science studies. I’m now three months into working with Databricks and loving every bit of it. I hope this path will eventually take me into a data scientist or AI Ethics role—and I’m looking forward to the ride.
The last T-SQL Tuesday of the year is hosted by my good friend Mike Walsh. Mike’s call for us is to end the year on a poignant note – write a note each to your past me and future me, on things you wish you knew, or learning plans or anything you’d like to say.
My notes are as below –
Note to My Past Self (10 Years Ago)
I wish you had realized that admiring others shouldn’t make you lose sight of your own worth and potential.
I wish you knew that real friendships take time to grow.
I wish you understood that if all you share with someone are conversations about community politics and tech, that relationship probably won’t last.
I wish you expected people to ask about you too—not just the other way around.
I wish you learned to let go and move on easily—whether from people or jobs that have outlived their value.
I wish you knew how to pick your battles and not let every little thing upset you.
But despite all this, you did your best. Life is a learning experience, after all.
Note to My Future Self
I’m glad you’ve learned to find joy in doing things for their own sake—not for rewards, even in tech.
I’m glad you kept learning what you wanted to learn, despite the challenges.
I’m glad you figured out who your true friends are—and held on to them.
I’m glad you learned to trust life and let go of what doesn’t matter.
And I’m glad you still find time to smell the roses and be grateful.
As we close out the year, I’m reminded that growth is a journey—one that stretches across decades, shaped by lessons learned and hopes carried forward. Here’s to continuing that journey with curiosity, resilience, and gratitude. Thank you Mike, for hosting and wishing everyone a happy and safe holiday season.
This month’s TSQL Tuesday invite is from my good friend, long standing MVP and community volunteer Taiob Ali – Taiob’s call is to blog on how AI, (the biggest invention since the internet, according to some) is changing our careers.
The place I work is passionate about AI adoption. We are exploring many tools in that regard. I may not be able to share details of exact usage for privacy reasons. These are my personal experiences.
How I use it personally
I have not played with many AI tools. I use a paid version of ChatGPT, which I find helpful for the following reasons.
1 To generate small amounts of test data for demo and other reasons. It is very good at this – especially if I can provide table(s) and ask it to generate Insert statements. 2 To review my blog post and ask for suggestions on English, or if it matches the tone I have in mind. 3 For occasional art generation – such as some thank you card logos for events like SQL Saturday. I have had some experiences there that I can blog about separately. 4 For simplifying complex text in research papers – I must read a lot of research papers for school, and sometimes the language is too hard for me to follow. So, I ask for help with one paragraph at a time. It is not capable of condensing all of it. By the way, it gets worse with more data, and it has little memory for what you asked earlier. Even with these limitations, it can be helpful. 5 For assistance with R Programming. Maybe because R is an open-source product, the help you can get is fantastic and saves you hours. I do not cut and paste any code; I ask it specific questions like ‘how do I increase font on legend with this scatterplot’.
My experience so far is that it is another tool in my toolkit. While I have not had transformative experiences yet, it has proven to be helpful in my daily work. I also have thoughts on ethical challenges and concerns with mental health that it causes. For my own sanity – I do not address it or talk to it like a person. Nor do I engage in experiments like some do – like debate it on what it says or try to get some cool answer they can share on social media about it. It is strongly ‘it’ to me, not a person with reasoning skills or feelings.
Some of the links that I have found helpful in that regard are below.
Resources that I recommend.
Harvard neuroscientist Dr Srini Pillay’s interview on balanced usage of AI, with warnings on the impact on the brain if used too much. This is not a pro or anti AI talk – it is very pragmatic and eye-opening on how much and why we need to use these tools. Dr Pillay explains how to find balance in the confusing world we are in by using AI appropriately and paving the way for healthy, innovative outcomes.
A research study shared by my colleague Mark Wilkinson found that AI does not necessarily improve productivity among programmers. This study is based on a small sample of programmers and has interesting findings related to higher productivity.
Stack Overflow 2025 survey results related to AI – of particular interest is the # of people using it at work, challenges with trust, AI tools versus AI agent usage. Also has a dataset we can use to explore further – the largest dataset of developer opinions available.
Long-time SQL Server MVP and data scientist Kevin Feasel, who is my go-to guy for all things data science related, wisely pointed out that Generative AI is hardly the only form of AI. It is easy to forget this critical fact, given that the term AI is used to refer to just generative AI these days. Here is a blog post teaching us about other forms of AI.
Ethical considerations
Last but hardly least, there are lots of ethical issues surrounding AI. My humble research using Stack Overflow data from last year (still a work in progress) is here. I follow an Australian researcher named Kate Crawford, who has written a fantastic book called ‘Atlas of AI’. She highlights what goes into AI in the form of environmental resources, cheap labor, and many other factors. She also has many talks on YouTube that are worth listening to.
Data Platform MVP and longtime volunteer/mentor Eugene Meidinger has a great post on AI Ethics about Power BI. I loved one of his quotes – to always paste ‘into’ it and not ‘out of ‘it.
Conclusion
All of this said, AI is a game-changer, like it or not. There are basically two strong stances about its future – one that thinks it will die down, if not go away, because of how much garbage goes into it over time, and the second that says it will pave the way for a new future. Most of us are, safe to say, in the middle and confused about where we are going to land with it. My own stance – use it limitedly, stay informed and rely on educated resources, be open to possibilities, and stay grounded in your ethical stances.
AI is considered the new superpower. The adoption of AI in various capacities is at 72% across industries, worldwide, according to one study, and it does not show signs of slowing down. Meanwhile, concerns about ethical issues surrounding AI are also high. According to a Pew Research report published in April 2025, more than 60% of the general public polled expressed concerns about misinformation, the security of their data, and bias or discrimination. As database technologists and software developers, we play a crucial role in this evolution. A 2024 GitHub research survey indicated that more than 97% of respondents were already using AI for coding. Many of us may also be involved in developing AI-based software in various forms. But how aware and conscious are we of ethical issues surrounding AI? Granted, our usage of AI may be driven by work-related reasons, but what about our own personal stances? Are we aware of ethical issues, and do these issues factor into our perception of AI in any way?
Studies reveal that developers exhibit only moderate familiarity with ethical frameworks, including fairness, transparency, and accountability. According to a 2025 survey of 874 AI incidents, 32.1% of developer participants had taken no action to address ethical challenges. (Zahedi, Jiang, Davis, 2025). Another study in 2024 proved the need for ‘comprehensive frameworks to fully operationalize Responsible AI principles in software engineering.’(Leca, Bento,Santos, 2024).
The purpose of this blog post is to look at ethical concerns related to AI as expressed by developers in the Stack Overflow Developer Survey, 2024.
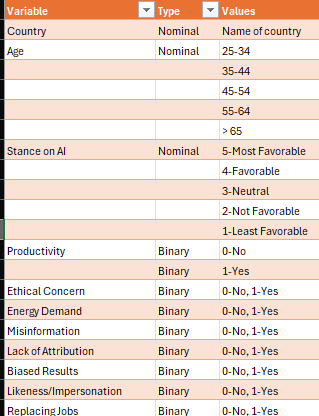
The dataset comprises 41,999 observations (after cleansing for individuals under 18 and those without stances on AI) across developers in 181 countries. After the transformations, it appears as follows.
The questions I want to analyze, with the concerned variables, are as follows.
1. How do ethical concerns correlate to how favorable or unfavorable the stance is?
The outcome (Stance on AI) as related to the potential predictor (The six ethical concerns- biased results, misinformation, lack of attribution, energy demand, impersonation or likeness, and the potential for replacing jobs without creating new ones).
2. How does productivity as a gain correlate to how favorable or unfavorable the stance is?
The outcome (Stance on AI), as related to the potential predictor (Productivity Gain).
3 How does productivity as a gain, combined with ethical concerns, correlate to how favorable or unfavorable the stance is? The outcome (Stance on AI) as related to the potential predictor (Productivity Gain), along with the six ethical concerns.
4 How does bias as an ethical issue and the age of the developer relate to the stance of AI? The outcome (Stance on AI) as related to bias as an ethical issue, along with the respondent’s age bracket.
Methodology
The outcome being analyzed for all four questions is the AI stance, a Likert scale with 5 values in increasing order. (This is a dummy variable created based on verbiage-based responses in the original.) The ‘predictor’ variables, or the ones whose impact we are analyzing (Ethical values and productivity), are binary. Age, which is the variable considered in the last question, is a categorical one with age brackets. I have used ‘odds ratios’ and ‘predicted probability’ to explain findings, as they are simple and easy to understand. ‘Odds Ratio’ means the chances or odds of a favorable AI Stance over a neutral or unfavorable one. Predicted probability is the chance of an event (in this case, a change in stance on AI) happening out of all possibilities.
Descriptive Statistics of the dataset
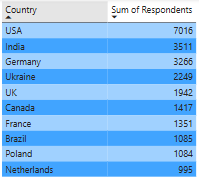
The top ten countries with respondents are as follows, with the US having a significantly high # of people. This may be since the US has a significantly high number of developers in general. It also means views overall may be mainly skewed in favor of US respondents. For this analysis, I have not filtered the dataset by country, although this may be a worthwhile consideration for the next phase.
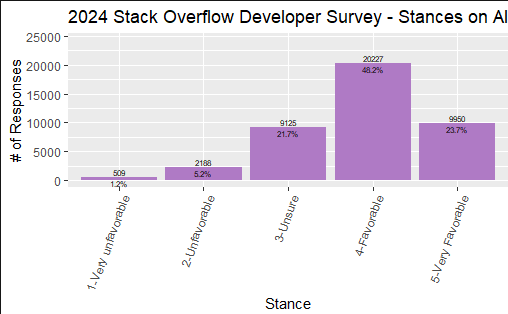
Stances on AI were overwhelmingly positive, with nearly half the respondents (48.2%) rating it as most favorable. Just 1.2% rated it as very unfavorable, with the rest falling between the two extremes.
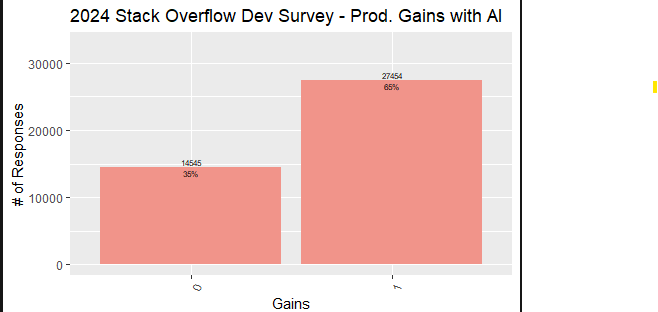
65% of respondents reported productivity gains with AI.
There were a total of six ethical concerns: biased results, misinformation, lack of attribution, energy demand, impersonation or likeness, and the potential for replacing jobs without creating new ones. (Some more were too custom to be included for analysis.) The majority of respondents had more than one ethical concern. Misinformation (25.8%) and lack of attribution (21.03%) ranked highest among the concerns. Very few respondents (2.11%) had no ethical concerns.
Question 1: How do ethical concerns correlate to how favorable or unfavorable the stance is?
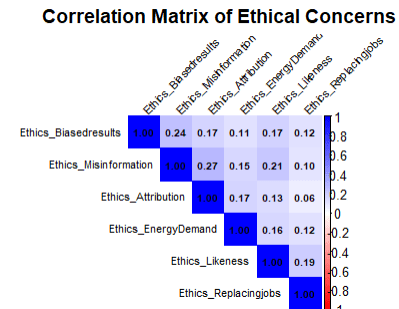
I decided to group all the ethical concerns and weigh them against the stance. This is because most respondents have multiple ethical concerns. I also verified whether concerns overlap (i.e., the impact of one ethical concern is addressed by another – a term in statistics called ‘multicollinearity’). This was not the case, as demonstrated by the image below. (Values on the boxes are minimal compared to 1).
The results of the analysis were as follows.
Data Source: 2024 Stack Overflow Developer Survey
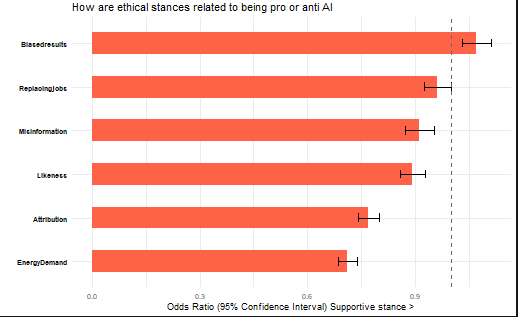
Odds are the ratio of an event happening to its not happening. In our case, the ‘event’ is a possibility of a lower stance. Except for biased results, all other ethical concerns have odds of less than 1, indicating a less favorable stance. Even with biased results, there is only a slight increase in stance, and that may be related to other factors we have not considered. Energy demand seems to have the highest correlation to lowered stances.
Question 2: How does productivity as a gain correlate to how favorable or unfavorable the stance is?
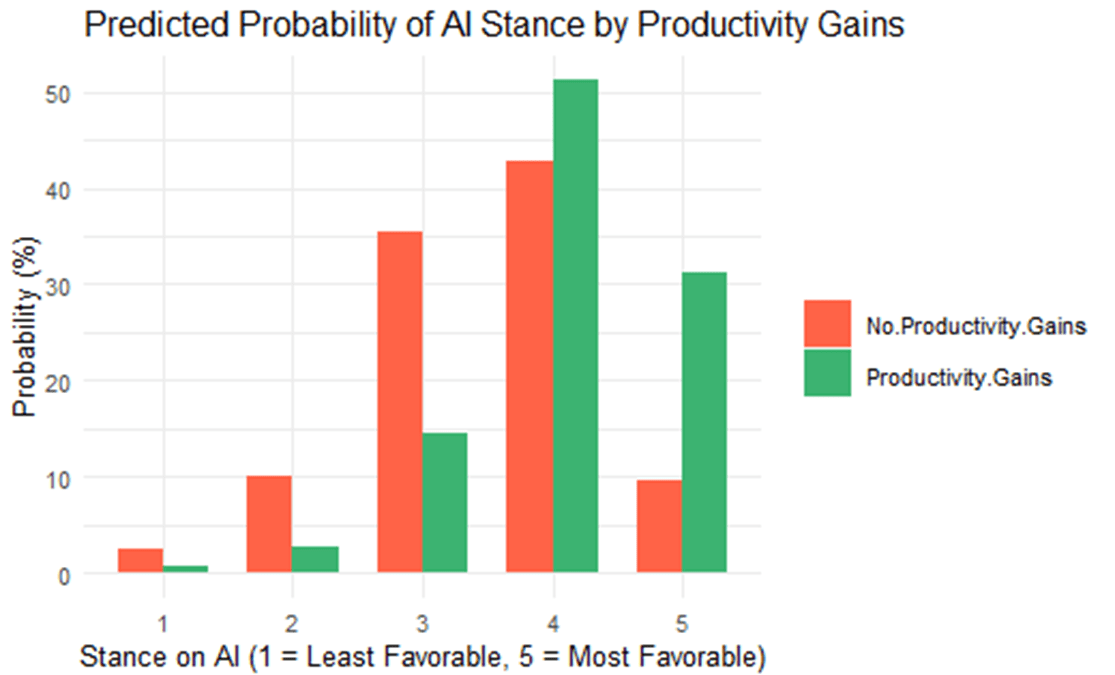
Predicted probability is the chance of an event (in this case, a change in stance on AI) happening out of all possibilities. The graph shows that the chances of a high stance (4 or 5) have a high probability of achieving higher productivity gains (tall green bars). However, it also shows that these stances are taken by those with no productivity gains (the red bars are also high for stance 4, although not very high for stance 5). Many people with no productivity gains exhibit a moderate stance (tall red bar with 3).
Data Source: 2024 Stack Overflow Developer Survey
People in the oldest age bracket (over 65 years old) appear to take a less favorable stance, which seems significantly higher compared to the youngest age bracket of 25-34 years old. How does productivity as a gain, combined with ethical concerns, correlate to how favorable or unfavorable the stance is?
Question 3: How does productivity as a gain, combined with ethical concerns, correlate to how favorable or unfavorable the stance is?
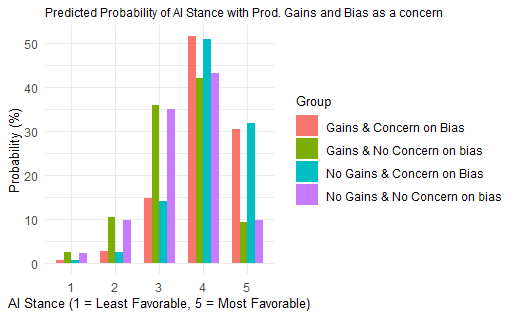
This question examines how stances on AI change when considering both ethical issues and productivity factors. Out of the six ethical issues, I chose two – concerns around bias and misinformation. The charts are as below, and were mostly similar. There are 4 buckets the data falls into – 1 Those with gains and concerns (red) 2 Those with gains and no concerns (green) 3 Those with no gains and concerns and (blue) 4 Those with no gains and no concerns. (purple)
Data Source: 2024 Stack Overflow Developer Survey
All things being equal, those with gains and concerns (red bar) show highly favorable stances (4 or 5). All things being equal, those with gains and no concerns (green bar) also show neutral to favorable, but not highly favorable – perhaps other factors related to usage may be at play here. All things being equal, those with no gains and concerns tend to be moderate to favorable, with some also being less favorable (blue bar). All things being equal, those with no gains and no concerns seem to lean towards neutral to favorable. (purple).
It may seem odd that those with no gains and no concerns seem to have favorable stances. There may be other variables at play here that we have not considered, such as gains other than productivity, for example. This again is something to examine during the next phase of analysis.
Overall, productivity gains appear to show more favorable stances (green and red bars).
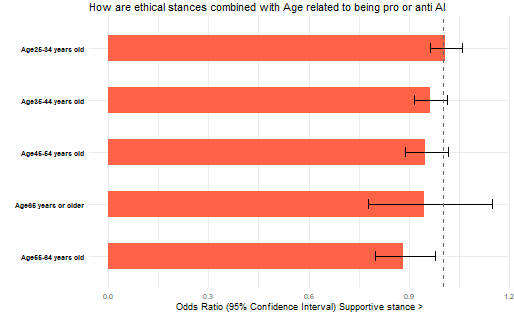
Question 4: How does bias as an ethical issue and the age of the developer relate to the stance of AI?
Adding age to the bias as an ethical issue and analyzing it with stances on AI is presented below.
Source: 2024 Stack Overflow Developer Survey
All things being equal, the odds of people in the oldest age bracket (over 65 years old) taking a less favorable stance seem significantly higher compared to those in the youngest age bracket (25-34 years old).
Results
1 How do ethical concerns correlate to how favorable or unfavorable the stance is?
This analysis focused on the outcome (Stance on AI) as correlated to the potential predictor (the six ethical concerns: biased results, misinformation, lack of attribution, energy demand, impersonation or likeness, and the potential for replacing jobs without creating new ones). Energy Demand as a concern appeared to have the highest correlation to less favorable stances. All other ethical issues exhibited a correlation with less favorable stances, except for bias, which showed a slightly positive correlation.
2. How does productivity as a gain correlate to how favorable or unfavorable the stance is?
This analysis focused on the outcome (Stance on AI) as related to the potential predictor (Productivity Gain). Productivity gains are associated significantly with higher stances, although the lack of those doesn’t necessarily mean lower stances.
3 How does productivity as a gain, combined with ethical concerns, correlate to how favorable or unfavorable the stance is? This question led to analyzing the outcome (Stance on AI) in relation to the potential predictor (Productivity Gain), along with the six ethical concerns.
Those with gains and concerns show highly favorable stances. Those with gains and no concerns exhibit neutral to favorable attitudes, but not highly favorable ones. Those with no gains and concerns seem moderate to favorable, with some also expressing less favorable views. Those with no gains and no concerns seem to lean neutral to favorable.
4 How does bias as an ethical issue and the age of the developer relate to the stance of AI? The last analysis examined the outcome (Stance on AI) as related to bias as an ethical issue, considering the respondent’s age bracket. People in the oldest age bracket (over 65 years old) appear to take a less favorable stance, which seems significantly higher compared to the youngest age bracket of 25-34 years old.
Key findings summarized
The majority of respondents have expressed ethical issues.
Energy Demand as a concern appeared to have the highest correlation to less favorable stances.
All other ethical issues had a correlation with less favorable stances, except bias.
Productivity gains seemed associated with higher stances despite ethical concerns.
Bias and misinformation as concerns do not appear to significantly impact higher stances.
Favorable stances appear to be high overall, regardless of productivity or ethical issues.
Further work Examine the impact of other gains besides productivity. Filter the dataset by specific countries for more insight into country-specific data.
Limitations
It is critical to bear in mind that correlation <> causation, and that favorable or less favorable stances do not necessarily have to reflect ethical concern or lack of it. However, given the patterns found, it is worth researching further to explore possible deeper relations to demographics (country, age), and also filtering the dataset by specific countries to gain more insight. The dataset is also limited to developers, not specifically those working on AI, although some of them may be. Perspectives and findings may vary with a dataset of AI Developers. The dataset is also heavily skewed in terms of respondents from the USA compared to those from other countries.
Gao, H., Zahedi, M., Jiang, W., Lin, H. Y., Davis, J., & Treude, C. (2025). AI Safety in the Eyes of the Downstream Developer: A First Look at Concerns, Practices, and Challenges.
I attended the PASS Data Community Summit held in Seattle in person this year after a long gap of 4 years and after RedGate software took over running the summit.
The place I work at had stopped paying for in-person training – making it an expensive decision to attend if I wanted to. I had not submitted to speak or planned on attending until about August when my boss found a backlog of unused vacation I had and needed to use before the year ended. I had plenty of vacation, was also able to secure airline tickets based on my points, got affordable Airbnb accommodation close to the convention center, and booked a trip to India after the summit. In short, it was meant to happen, and it did.
Some specific observations are as below.
1. The new convention center was an amazing location. The distance to classrooms was optimal and not a hike like at the older place. It was a modern building with several areas to sit around, and network, and huge glass panes let in sunlight. It made for a great experience.
2 RedGate did an amazing job with organizing. Everything was very smooth, starting with registration. There were many opportunities to network, even if one was not a party or late-night person. Coffee and tea were set up all day until 5 p.m. Friday. 3 The ‘Experts’ clinic, which replaced MSFT’s SQL clinic, was staffed by MVPs/consultants and seemed a huge success. People lined up all day and seemed to get the answers they needed. 4 There were many case study presentations—moves to AWS/Azure seemed to make for several. 5. I was invited to one of several closed-door discussions on tech careers, managing data in the cloud, and other topics. Several people expressed frustrations about hasty moves to the cloud and how much they cost their company. Some felt these costs were passed down as pay cuts and low salaries. I was also selected to be interviewed by Louis Davidson, one of my #sqlheroes and among the senior community members I look up to. It was a great conversation. 6 The ‘community zone’ was set up away from dining rooms and classrooms, making it a place specifically for people to hang out and engage in conversation. It worked amazingly well. There were informal sessions here, too—I got to do one on mentoring and community with my good friend Chris Yates and greatly enjoyed it. There were sessions on hobbies and various fun activities here, too.
7 Very few MSFT employees were present on site. Several took time to drive in to meet friends on their own. I was very touched personally that they took time for me. I hope the formal presence of MSFT will improve at future summits; if not, the conference will take on a very different shape. For the first time in history, the new SQL server version was not announced at the Summit. 8 RedGate put up a Postgres conference in the same venue for half the cost. Both conferences shared the vendor area. It was a good move and made it possible for me to meet some amazing people – particularly Adam Machanic, one of my sqlheroes, and Karen Schuler, my good friend and long time community volunteer from Louisville.
9 I had a list of newer folks in the community whom I wanted to meet. I ended up meeting many more. It was a positive experience, and I felt good about the future of the community—although it would be very different from the one I was used to.
Observations not directly related to summit
1. Many people I talked to felt confused and worried about the job market. SQL Server, as a hardcore technical skill, seemed less in demand, although it is very much around. The ‘other’ skills needed were spread over a wide spectrum, ranging from NoSQL Platforms to AI technologies. The pay was much lower than five years ago, and in-person work is primarily expected.
2 Several people felt that SQL Server as product was not getting as much love from MSFT compared to Fabric and AI. What that means for us career wise remains to be seen and to me , strongly related to how many years of work one has ahead before retirement. It is, for sure, time to adapt and learn a lot more stuff.
3 The loss of Twitter/X as the main networking platform was felt and missed deeply. The only social event I attended personally was the RedGate volunteer party. I had lunches/dinners with several friends in private and headed home early on most nights. Granted, this was a choice for me – but one did not even know of other social events, formal or informal, because there wasn’t a platform to communicate as a community any more.
4 Grant Fritchey talks of his word of choice to describe the year as ‘fragmented’. That would be my choice, too – especially with the community. Many people we used to hang out with have retired, moved on to doing other work, and many have intentionally limited their contacts. I realize that the ‘glue’ that kept us friends was community politics, common technology (SQL Server), and the many in-person events where we used to see each other – before 2020. The politics is different now. The technology has expanded to many other platforms, and in-person events are drastically low. That, combined with losing X, leads to a highly fragmented community.
I missed the older, bigger crowd – but the friends who sought me out and who I have now are those who want to stay in touch because they value me as a person over politics/technology/and other common talk topics. In other words, the ‘real’ people I want in my life. That is nothing but a good thing.
I hope to attend PASS Summit 2025 to deepen a few existing friendships and make newer connections, as well as learn and share our concerns about where we are heading. I want to thank RedGate Software sincerely for making me feel welcome and helping me participate in many ways.
I was privileged to host yet another T-SQL Tuesday, for the month of August, 2024. My topic was on Managing database code. I was worried about getting responses, given that most of the community is no longer on X/Twitter and my invite didn’t seem to get much attention. I was wrong. People seem to keep track of this by other means and the response was excellent. Summary as below.
Kevin Chant (b/l) talks of his experience and preferences around repos and CI/CD pipelines using Azure Devops/Github for SQL Server, SQL Pools and Microsoft Fabric Data Warehouses. He talks about using Projects for doing state based migration and migration based deployments, where repo structure can be quite different from a standard one. His post has a lot of links to technologies he has used and includes an invite to engage with him, for those who want to learn more.
Long time Data Platform MVP, MCM and friend from down under – Rob Farley (b|l) differentiates between ‘where the database code lives’ and ‘where do you keep your database code’ . From a consultant’s perspective, I can totally understand the difference between those two questions. It was revealing to me, that as a full-time employee for six years, that difference did not even occur to me because we inherently own what we manage. He talks of doing whatever fits in with the client’s existing processes – while recommending a script-based repository if they don’t have one. He also seems to use the method as I do personally – Powershell based SMO, to script out objects.
Well known conference speaker/DEI Champion and Data Platform MVP Deepthi Goguri (b|l) talks of a simple version control process using RedGate source control and GIT, that she uses where she works.
Tom (b) talks of 3 approaches to version scripts – a state-based approach, a migration-based approach and a hybrid approach. They talk of the common aversion to consider database code as repo worthy as well.
Data Platform MVP, Conference speaker and WIT champion Deborah Melkin (b|t) writes about many types of scripts and their importance to workflow for database developers. She emphasizes the importance of having code in source control, regardless of how one chooses to do it. She also has a session on ‘Database deployments demystified’ for this. I found the recording here and recommend it.
Andy Levy (b|l) blogs about usual Visual Studio database projects along with powershell to generate scripts and keep up the SQL Server based repo he manages. He also speaks of managing a MySQL repo with just scripts needed for changes, and having large swaths of code that is not in the repo.
Data Platform MVP Eitan Blumin(b|l) blogs about the advantages of GIT over TFS/VSS, and his favorite tool for CI/CD, Azure Devops. He also explains the advantages of SSDT over other tools in detail.
Data Platform MVP, speaker and author Richard Swinbank(b|l) talks of basic principles behind code management (resilience, repeatability), and the process he uses to manage code.
Jeff Mlaker(b) talks of the pitfalls of not using source control for database code, with some interesting personal stories including one on merging different versions of code when no source control existed.
Lastly, long time Data Platform MVP, DevOps Advocate and currently owner of the T-SQL Tuesday blog series, Steve Jones(b|l), talks of the importance of getting code into repo and the tools he uses to accomplish the same.
This is my T-SQL Tuesday #5. It is a great way to understand multiple perspectives and experiences around a topic, get more blog traffic and gain more contacts to add to your community. Contact Steve if you wish to host one.
Thank you to everyone who responded here. Your responses enriched my knowledge of this subject and helped me find more community. #sqlfamily #sqlwinners.
This is my own contribution to the T-SQL Tuesday I am hosting – on managing database code.
I am from the older generation – where the farthest we went with managing code was use VSS/TFS to get the latest version and deploy it. In some cases, I’ve managed it. If we wanted to search for existence of an object or its usage, we simply searched the database – using some custom tools/dmvs or 3rd party tools like RedGate’s SQL Search. History of who changed what – well that came from their tickets or if it was code – from code comment history. With the advent of GIT, all that changed. I did not adapt to GIT very quickly. I went, kicking and screaming. I hated the clunky interface. I hated not knowing what the command actually did, but still had to use it. I did not see the point of learning what I thought to be over engineered version control. But over time, I’ve learned its value. I can find almost any code that has been committed. I can see who changed what, and when, very easily. I can search for code usage and objects, really quickly. Granted, the interface is still clunky and merge conflicts aren’t fun when they happen, but the advantages override all that, significantly. There is one place where we can easily see all the code related to a database. We can evaluate how complex it is and even use it for legal reasons as code base of the company.
As of now, I use GIT for source control extensively. At work all our database objects are scripted out and have their repo. When we make a change, the new objects are auto scripted with the changes.
I am a fan of SMO, for this purpose and have scripts I’ve developed myself. Granted, SMO only works for SQL Server. I am learning more on similar tools for Postgres. I am often frustrated that Redshift has none. I strongly advocate using GIT and putting all your database objects into a repo using whatever means you can get. (Or develop your own means). It is worth a lot more than you think.
I am excited to host the T-SQL Tuesday blog party for August 2024. I’ve done this many times, but I always remember when I was new to the community and how much it helped me gain recognition. Thanks to Adam Machanic for starting this initiative and to Steve Jones for keeping it going.
This month’s topic is ‘Managing Database Code’. I initially called it ‘How do you manage your database repo?’, but Steve pointed out that many people in the database community might not know what a ‘repo’ is. So, we simplified it to ‘Managing Database Code’. Managing code has been a big part of my work as a database engineer for the past six years.
A repo, for those who are not aware, is just short for ‘repository‘, a place to store stuff. In this context, a place where ‘keep’ code. It is version control for code. I remember the days before repos were common. We used tools like VSS/TFS and searched through tickets and comments to track changes. We used DMV-based queries to find objects. Now, with repos, everything is much easier. I can’t imagine working without one.
I’m curious about how others manage their database code. Here are some questions to consider:
Where do you keep your database code? Is it in a GIT-based repo, or just in the database the old-fashioned way?
If it is in a repo, how is it created? Do you script out individual scripts and add them, or do you use tools to script out the entire database, like SSMS scripter, SMO-based scripts, or third-party tools? This could apply to any relational database, not just SQL Server.
How do you keep your repo up to date when code changes? Depending on what your shop does, you may or may not have a well evolved CI/CD pipeline. If you do, explain how it works. If you don’t, that’s fine – we just want to know where the code resides, if it is outside the database.
If you don’t have a repo, why not? How do you manage things like searching code or finding who made changes and when?
I look forward to reading your responses. The rules
Publish your post on Tuesday 13th of August , time zone does not matter.
Include the T-SQL Tuesday logo at the top of your post and link it back to this invitation post.
A comment letting me know you have a contribution is ideal but if that’s not doable, just send me an email!)
If you’re on X/Twitter, share your post using #tsql2sday.
I recently graduated with a Master’s in Strategic Communication from the University of Delaware. Attending the graduation ceremony with my sister made it a truly memorable experience.
Here’s a bit about why I chose this degree and what’s next for me.
During the Covid crisis, I sought a new focus amid the trauma and confusion of losing four dear family members, including my Dad. Initially, I looked into Data Science programs, but many were beyond my budget or required prerequisites I couldn’t meet. I held a three-year bachelor’s degree and a three year masters (MBA) from India, from over 30 years ago. Degree evaluation is possible but course by course transcript evaluation is rather difficult. Also most programs needed a 4 year bachelors, not 3.
Online master’s programs were also very limited at the time, so I opted for this degree as a stepping stone towards future studies in Data science and analytics. I appreciated the curriculum and the school, especially the courses on sales, PR, and sales data analytics, which I formerly knew very little of and found fascinating. I also made good friends among my classmates and faculty. Graduating with an A has positioned me well for pursuing further studies more aligned with my professional interests.
Now, I am applying to three Data Analytics programs. While some might find it unusual to jump into another demanding master’s program so soon, I see it differently. I love learning in an academic setting and believe it will enhance my career prospects significantly, if I make the right choices on the degree and learn with it.
A big thanks to friends in the community who supported and inspired me on this journey – Blythe Morrow, Randolph West, Kevin Kline, Joe Fleming, Cindy Gross and Daniel Maenle. I am grateful for your support and your friendship.
My dear friend Josephine Bush a.k.a HelloSQLKitty hosts this month’s T-SQL Tuesday. Josephine’s call to us is to share our understanding of the multitude of job titles available out there and what they mean to us.
While many job titles exist, each role’s essence is heavily shaped by the operational dynamics of the business and how responsibilities are allocated among individuals. A rough and high-level comprehension of these titles can be outlined as follows:
Database Administrator (DBA): Responsible for High Availability/Disaster Recovery (HA/DR), Backups/Restores, security measures, including audits, storage management, code promotions, and sometimes even code reviews. Encompasses Continuous Integration/Continuous Deployment (CI/CD) and automation, and may also be referred to as a ‘Database Reliability Engineer’.
Database Engineer (DBE): Tasked with managing database code, architecture, and data process flow. Engages in Extract, Transform, Load (ETL) processes, pipelines, and assumes responsibility for data integrity and health.
Database Architect: Often involves a blend of DBA and DBE roles, with a substantial infusion of cloud architecture expertise.
Data Warehouse Engineer/BI Architect: Primarily concerned with reporting, data warehousing, and data lake management.
Data Scientist: Typically held by individuals with Ph.D. qualifications or similar expertise, focusing on algorithms and predictive analytics.
Having devoted close to two decades to the role of a DBA, I began experiencing weariness around 2018. The toll of being on-call was manifesting as severe health implications. In most settings, DBAs were perceived as reactive problem solvers—earning high remuneration but receiving little attention or respect unless a crisis demanded their intervention. In essence, proactive contributions were unacknowledged, and one’s worth was not recognized as value-added to the business. This prompted me to explore alternative roles. I authored a book for Apress, wherein I engaged with various community members to delve into their roles and responsibilities. After interviewing 29 professionals, I arrived at three viable options:
Delve deeper into Business Intelligence (BI) and transition to reporting and BI-related responsibilities. While I had previously occupied a BI role, opportunities in this domain were limited.
Cultivate skills in Product Management and transition into a PM or DBA management role. However, the steep learning curve and the prospect of becoming extensively people-focused gave rise to uncertainty. Additionally, I was skeptical of the fervor around Agile methodologies, as I noticed elevated attrition rates among PMs.
Embrace a Data Engineer role that primarily involves coding and architecture. Among these choices, this resonated with me the most from a technical standpoint. While I was familiar with R Programming and comfortable with VB.net, I was uncertain whether these skills would suffice. Fortunately, the current job opening aligned with my skill set, enabling me to become a data engineer. Since transitioning, this role has proven to be one of the most fulfilling data-related experiences.
To conclude, the precise definitions of these titles are of secondary importance. The focus should lie on personal aspirations and whether a job aligns with those objectives. Thank you, Josephine, for hosting.