Continuing with the recipes in SQL Server 2012 T-SQL recipes book – I was drawn to this puzzle that asked for how you would compare data in two identical tables using a single query. Now, if they didn’t specify the means I would readily point them to Red Gate’s SQL Data Compare – a nifty great tool that does this kind of stuff and gives an awesome report on differences. But as we all know, not all companies have tools. And, if you are presented this question at an interview – that would probably not be an acceptable answer.
My answer to this problem is different from what is in the book – mainly because I wanted a generic query that I could use on any table. The book deals with grouping on a field-to-field basis which is table specific and would come in handy if the situation demands that.
My solution is as below – I took two tables in Adventureworks, Password and Passwordcopy which is an identical version of Password. I made some changes to the latter as below(updated two records, added one record and changed two more via management studio).

Now I ran query as below to give me differences.
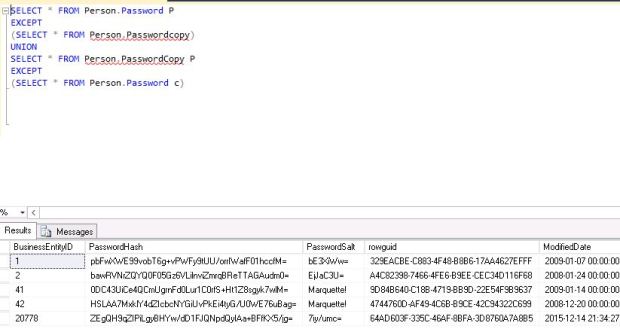
It gave me the differences I was looking for. I can run the first part of the query before union to see what of these came from first table and second part to see what is in the second. Of course, it is not SQL Data Compare – it does not tell me what the differences are but it is a simple easy way to get a look.